Maximal Margin Classifier
Maimum Margin Classifier uses hyper planes to find a separable boundary between linearly separable data points.
Suppose we have a set of data points with $p$ predictors and they belong to two classes given by $y_{i} = {-1 , 1}$. Suppose the points are perfectly separable through a hyperplane. Then the following hold \begin{alignat}{2} &\beta_{0} + \beta^{T}x_{i} &&> 0 \quad \text{when} \quad y_{i} = -1\newline \text{and} \quad &\beta_{0} + \beta^{T}x_{i} &&< 0 \quad \text{when} \quad y_{i} = 1\newline \implies y_{i}(&\beta_{0} + \beta^{T}x_{i}) &&> 0 \end{alignat}
Thus classification can be made into the positive or negative class simply based on the sign of the quantity $\beta^{T}x$. The further a point is, the more confident we will be in the classification.
Note that there can be infinite such hyperplanes that perfectly separate the data, and each can be obtained by slightly perturbing the given plane. Define margin as the minimum perpendicular distance from all training observations to this plane. The maximum margin classifier will be the one for which this margin is maximum.
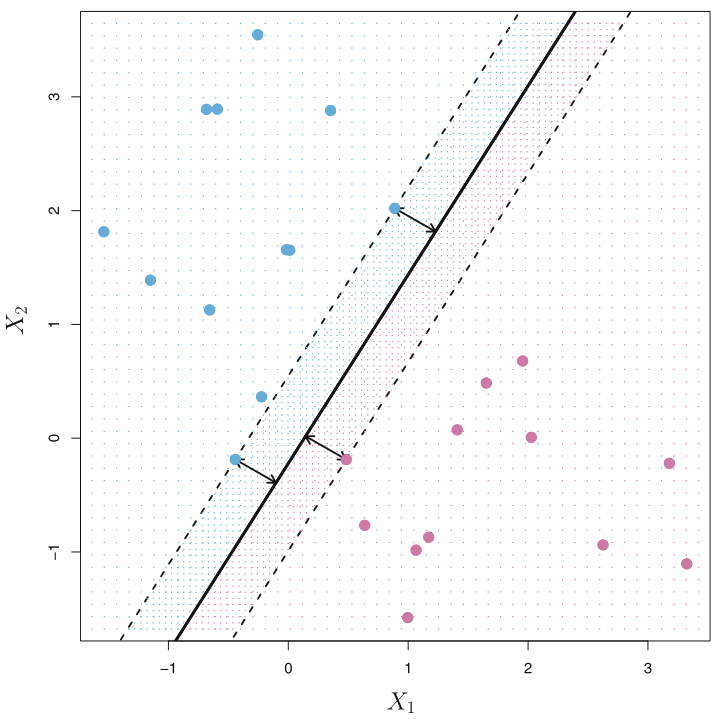
Note that the location of the maximal margin is determined only by the points closest to the boundary. If a point farther away would slightly move, the boundary would still be the same. Whereas if the point closer to the boundary would shift, the boundary itself would change as can be seen in the figure above. These set of observations are know as support vectors. And by symmetry, the perpendicular distances of these closest points from the plane are same.
Algorithm
Finding the boundary is same as solving for the following optimization problem ($M$ is the margin) \begin{align} &\maximize_{\beta_{0}, \beta} M\newline &\text{subject to} \quad \sum_{i=1}^{p} \beta_{i}^{2} = 1,\newline &\text{and} \quad y_{i}(\beta_{0} + \beta^{T}x_{i}) \geq M \quad \forall \quad i = 1, 2, \ldots, N \end{align} The constraint $\sum_{i=1}^{p} \beta_{i}^{2} = 1$ gives rise to the unique property that $\beta_{0} + \beta^{T}x$ is the perpendicular distance of the point $x$ from the hyperplane, making the last constraint equation valid.
By using the perpendicular distance using the equation from appendix, we can replace the constraint on the norm and rewrite as \begin{align} &\maximize_{\beta_{0}, \beta} M\newline &\text{subject to} \quad y_{i}(\beta_{0} + \beta^{T}x_{i}) \geq M \lVert \beta \rVert \quad \forall \quad i = 1, 2, \ldots, N \end{align}
Note that the last equation remains same when we multiply by a positive constant. Hence, we can choose $\lVert \beta \rVert = 1/M$ for simplicity and the maximization problem becomes a minimization one (a factor of $1/2$ is introduced to simplify the derivative of the square term) \begin{align} &\minimize_{\beta_{0}, \beta} \frac{1}{2}\lVert \beta \rVert^{2}\newline &\text{subject to} 1 - \quad y_{i}(\beta_{0} + \beta^{T}x_{i}) \leq 0 \quad \forall \quad i = 1, 2, \ldots, N \end{align}
For the following derivations involving linear optimization, refer to appendix.
Invoking the Lagrangian multipliers, the new optimization problem is \begin{align} \minimize_{\beta_{0},\beta} \frac{1}{2}\lVert \beta \rVert^{2} - \sum_{j=1}^{N} \lambda_{j} (y_{j}(\beta_{0} + \beta^{T}x_{j}) - 1) \end{align}
where $\lambda = (\lambda_{1}, \ldots \lambda_{N})^{T}$. Using the Wolfe Dual, the following is the dual problem
\begin{align} \maximize_{\beta, \beta_{0}, \lambda} L(\beta, \beta_{0}, \lambda) = \frac{1}{2}\lVert \beta \rVert^{2} - \sum_{j=1}^{N} \lambda_{j} (y_{j}(\beta_{0} + \beta^{T}x_{j}) - 1)\newline \text{subject to} \quad \lambda > 0, \quad \frac{\partial L}{\partial \beta} = 0 \quad \text{and} \quad \frac{\partial L}{\partial \beta_{0}} = 0 \end{align}
The partial derivatives give \begin{align} \beta = \sum_{j=1}^{N} \lambda_{j} y_{j}x_{j} \quad \text{and} \quad 0 = \sum_{j=1}^{N}\lambda_{j} y_{j} \end{align}
Substituiting in the dual, \begin{align} L(\lambda) &= \frac{1}{2}\beta^{T} \beta - \sum_{j=1}^{N} \lambda_{j} (y_{j}(\beta_{0} + \beta^{T}x_{j}) - 1)\newline &= \frac{1}{2}\beta^{T} \beta - \beta_{0}(\sum_{j=1}^{N} \lambda_{j} y_{j}) - \beta^{T}(\sum_{j=1}^{N} \lambda_{j} y_{j} x_{j}) + \sum_{j=1}^{N}\lambda_{j}\newline &= \frac{1}{2}\beta^{T} \beta - \beta_{0}(0) - \beta^{T} \beta + \sum_{j=1}^{N}\lambda_{j}\newline &= \sum_{j=1}^{N}\lambda_{j} - \frac{1}{2}\beta^{T} \beta = \sum_{j=1}^{N}\lambda_{j} - \frac{1}{2}(\sum_{i=1}^{N} \lambda_{i} y_{i}x_{i}^{T})(\sum_{j=1}^{N} \lambda_{j} y_{j}x_{j})\newline &= \sum_{j=1}^{N}\lambda_{j} - \frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \lambda_{i} \lambda_{j} y_{i}y_{j}x_{i}^{T}x_{j} \end{align}
along with the constraints, \begin{align} \maximize_{\lambda} \sum_{j=1}^{N}\lambda_{j} - \frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \lambda_{i} \lambda_{j} y_{i}y_{j}x_{i}^{T}x_{j}\newline \text{subject to} \quad \lambda > 0 \quad \text{and} \quad 0 = \sum_{j=1}^{N}\lambda_{j} y_{j} \end{align}
which is a quadratic optimization problem with linear constraints, and is solvable through linear optimization softwares. Maximizing the the dual will give us the lower bound of the optimal solution.
KKT conditions also need to be satisfied for the optimal solution, which gives \begin{align} \lambda_{j}^{*} (y_{j}(\beta_{0}^{*} + \beta^{*T}x_{j}) - 1 = 0 \quad \forall : j = 1, 2, \ldots N\newline \implies y_{j}(\beta_{0}^{*} + \beta^{*T}x_{j}) - 1 = 0 \quad \text{for points on margin}\newline \lambda_{j}^{*} = 0 \quad \text{for points away from the margin} \end{align} which is expected based on the definition of the problem as only the points on margin decide the separating hyperplane. The predictions for new data points are simply made on the basis of the sign of $\beta_{0}^{*} + \beta^{*T}x$